A few years ago, we started looking at Rust as a possible foundation for parts of the Crazyflie software ecosystem. At first, this was mostly exploratory work: experimenting with Rust on embedded systems, looking at WebAssembly, and investigating whether one communication implementation could be shared between several platforms and programming languages.
In Rust, Wasm and the Crazyflie, we explored what a Rust implementation of the Crazyflie communication stack could look like. Later, in Rust at Bitcraze, we described a somewhat more concrete direction: implementing the low-level Crazyflie communication and subsystem drivers in Rust and making them available to Python, C++, JavaScript and other environments.
At the time, this was still mostly a plan.
Since then, the Rust Crazyflie library has moved from a side project to an official Bitcraze project. It is used in production, has supported a number of tools and demonstrations, and is now becoming the foundation for the next version of our Python library.
With the first release of cflib2, this seems like a good time to look at where we are and how it relates to the direction we described a few years ago.
Why a shared Rust library?
The Crazyflie Python library, cflib, has been around for a long time and is used by a large part of the community. It is the reference library and so it supports most Crazyflie functionality and is the foundation of tools such as the Crazyflie client.
Over the years, we have also felt some of the limitations of its architecture. In particular, it has proved difficult to reach the level of communication performance we want for larger swarms. Improving this within the existing pure-Python implementation would require fairly deep changes which would require quite deep user-facing change (like going async) without a certainty of results.
A separate problem is supporting users working in languages other than Python. One community solution has been to maintain a semi-independent C++ implementation of the Crazyflie communication stack, the one used by Crazyswarm2. While this provides access from C++, it also means maintaining another implementation. New functionality usually lands in the Python library first and is only ported to C++ later, often when its absence becomes a pain point. Over time, this makes the ecosystem harder to keep consistent and maintain.
The Rust library addresses these two problems from different directions. It gives us a new foundation on which we can build a more efficient communication architecture, including better support for swarms. At the same time, it can act as a shared reference implementation for several languages. Native Rust applications can use it directly, while bindings can expose the same functionality to Python, C++ and other environments.
These two goals are mostly independent, but they reinforce each other. Instead of improving performance in one library and then reproducing the same work elsewhere, we can implement the communication and subsystem logic once and make it available to users regardless of the language they choose.
This does not mean that all Crazyflie users are expected to start writing Rust. Quite the opposite: one of the main goals is to make the advantages of the Rust implementation available while still allowing users to work in the language and environment that suit their application.
From an experiment to a useful library
The Rust Crazyflie library has gradually moved from being an experiment to something we can use in real applications.
It has been used in production test systems, development tools, demos and swarm experiments. In these applications, we have started to see some of the improvements we originally hoped for.
The library uses an asynchronous architecture, which makes it easier to manage multiple Crazyflies and several ongoing communication flows at the same time. It also gives us more freedom to improve how information is transferred between a Crazyflie and a computer.
For example, parameters no longer need to be downloaded during the initial connection; instead, they can be loaded lazily when they are first requested. This is the kind of functionality for which Rust’s type system and language features make it possible to build a clean architecture with a relatively straightforward implementation.
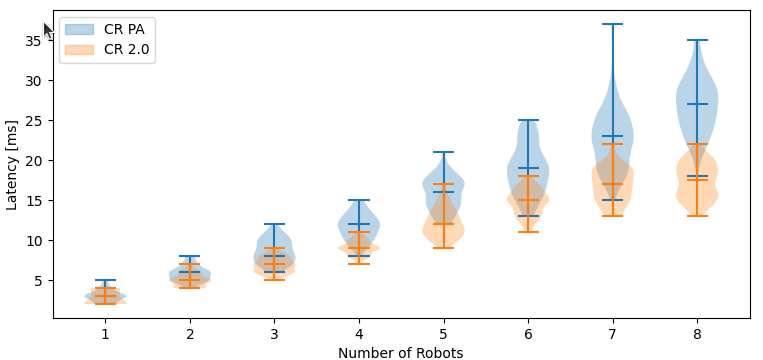
Individually, this kind of changes may sound fairly small, but together they can make connections faster and reduce the amount of radio communication required. This becomes especially visible when working with larger groups of Crazyflies.
We have already used the Rust library in demonstrations involving many Crazyflies connected through one Crazyradio 2.0. It is still an evolving implementation, but these experiments have shown that the new architecture can make a practical difference.
Bringing the Rust library to Python
Python remains one of the most important ways of working with the Crazyflie. For this reason, one of the main goals of the Rust library has always been to make it available through a Python API.
This is what we are now doing with cflib2.
cflib2 is a new, async-first Python library built on top of the Rust Crazyflie library. Its first release is now available on PyPI and the source code is available on GitHub.
Our intention is for cflib2 to become the official Python library for the Crazyflie and, in time, replace the current pure-Python cflib. We are not there yet, though. This is the first public release, made at a point where the library has started to see more use both internally at Bitcraze and by a number of early users.
cflib2 is not designed as a drop-in replacement for cflib. Its API has been designed again around an asynchronous model, and we are using the opportunity to reconsider some earlier design decisions.
Most of the communication and Crazyflie subsystem handling in cflib2 is implemented by the Rust library. The Python layer exposes this functionality in a form that should feel natural to Python users. This gives Python applications access to the same connection handling, caching and asynchronous communication used by native Rust applications.
We and a number of early users have already seen significant improvements when moving applications to cflib2. One visible example was our recent demonstration in which 49 Crazyflies were controlled through one Crazyradio 2.0. This was made possible by a combination of the new radio functionality and the architecture used by the Rust library and cflib2.
For now, cflib2 should still be considered a preview. A large part of the functionality is already available, and it is being used in real applications, but the API is not yet stable and breaking changes should be expected. The existing cflib therefore remains the official and established Python library today.
This first release is an important step towards making cflib2 the official library. Releasing it now allows more users to try it in real applications and gives us feedback while it is still possible to make larger changes to the API and architecture.
More than Python
Python is the first binding we are working seriously on, but it is not the only environment we have in mind.
The original idea was to use the Rust library as a common foundation for several languages and platforms. C++, WebAssembly and mobile applications are still possible directions.
In particular, we hope that the same Rust communication backend can eventually be used by future mobile Crazyflie clients. Sharing the implementation between platforms could make these clients easier to develop and maintain.
There is still work to do before all of this becomes available, and the exact shape of the different bindings is not decided. For now, cflib2 is the most concrete example of how the architecture can be used outside Rust itself.
The next step in the journey
Looking back at what we wrote in 2021 and 2023, the overall direction has remained surprisingly consistent.
We wanted to implement the lower levels of the Crazyflie communication stack once, use Rust where its properties were useful, and expose the result to the languages and platforms used by the community.
The Rust Crazyflie library and cflib2 do not complete that journey, but they are a significant next step.
For the first time, Python users can install a library based on the shared Rust implementation and start using it in their own applications. At the same time, we can continue improving the communication stack without having to reproduce every improvement separately in each language.
We are still learning what works well, and both the Rust library and cflib2 will continue to change. Feedback, bug reports and experiments using the new library are very welcome.
You can find the projects here:
It is nice to see that an idea we started exploring a few years ago is now becoming a useful part of the Crazyflie ecosystem.